Chaos Mesh Overview
This document describes the concepts, use cases, core strengths, and the architecture of Chaos Mesh.
Chaos Mesh Overview
Chaos Mesh is an open source cloud-native Chaos Engineering platform. It offers various types of fault simulation and has an enormous capability to orchestrate fault scenarios.
Using Chaos Mesh, you can conveniently simulate various abnormalities that might occur in reality during the development, testing, and production environments and find potential problems in the system. To lower the threshold for a Chaos Engineering project, Chaos Mesh provides you with a visualization operation. You can easily design your Chaos scenarios on the Web UI and monitor the status of Chaos experiments.
Core strengths
As the industry's leading Chaos testing platform, Chaos Mesh has the following core strengths:
- Stable core capabilities: Chaos Mesh originated from the core testing platform of TiDB, and inherited a lot of TiDB's existing test experience from its initial release.
- Fully authenticated: Chaos Mesh is used in numerous companies and organizations, such as Tencent and Meituan; It is also used in the testing systems of many well-known distributed systems, such as Apache APISIX and RabbitMQ.
- An easy-to-use system: Chaos Mesh makes full use of automation with graphical operations and Kubernetes-based usage.
- Cloud Native: Chaos Mesh supports Kubernetes environment with its powerful automation ability.
- Various fault simulation scenarios: Chaos Mesh covers most of the scenarios of basic fault simulation in the distributed testing system.
- Flexible experiment orchestration capabilities: You can design your own Chaos experiment scenarios on the platform, including multiple mixing experiments and application status checks.
- High security: Chaos Mesh is designed with multiple layers of security control and provides high security.
- An active community: Chaos Mesh is an incubating project hosted by CNCF. It has a growing number of contributors and adopters all over the world.
- Easily scalable: It's easy to add new fault test types and functions to Chaos Mesh.
Architecture overview
Chaos Mesh is built on Kubernetes CRD (Custom Resource Definition). To manage different Chaos experiments, Chaos Mesh defines multiple CRD types based on different fault types and implements separate Controllers for different CRD objects. Chaos Mesh primarily contains three components:
- Chaos Dashboard: The visualization component of Chaos Mesh. Chaos Dashboard offers a set of user-friendly web interfaces through which users can manipulate and observe Chaos experiments. At the same time, Chaos Dashboard also provides an RBAC permission management mechanism.
- Chaos Controller Manager: The core logical component of Chaos Mesh. Chaos Controller Manager is primarily responsible for the scheduling and management of Chaos experiments. This component contains several CRD Controllers, such as Workflow Controller, Scheduler Controller, and Controllers of various fault types.
- Chaos Daemon: The main executive component. Chaos Daemon runs in the DaemonSet mode and has the Privileged permission by default (which can be disabled). This component mainly interferes with specific network devices, file systems, kernels by hacking into the target Pod Namespace.
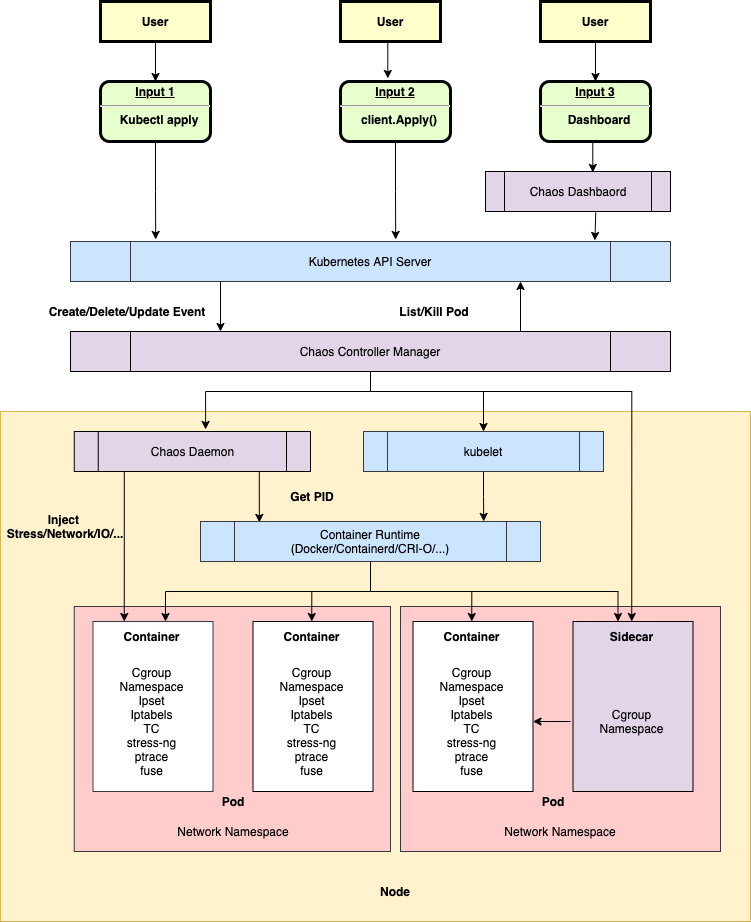
As shown in the above image, the overall architecture of Chaos Mesh can be divided into three parts from top to bottom:
- User input and observation: User input reaches the Kubernetes API Server starting with a user operation (User). Users do not directly interact with the Chaos Controller Manager. All user operations are eventually reflected as a Chaos resource change (such as the change of NetworkChaos resource).
- Monitor resource changes, schedule Workflow, and carry out Chaos experiments: The Chaos Controller Manager only accepts events from the Kubernetes API Server. These events describe the changes of a certain Chaos resource, such as a new Workflow object or the creation of a Chaos object.
- Injection of a specific node fault: The Chaos Daemon component is primarily responsible for accepting commands from the Chaos Controller Manager component, hacking into the target Pod's Namespace, and performing specific fault injections. For example, setting TC network rules, starting the stress-ng process to preempt CPU or memory resource.